
Can generative AI ("GPT Wrapper") be competitive with AWS Textract?
Specs for competitiveness:
- Textract API call vs. Gen AI call timing.
- Accuracy.
- Cost.
We'll be competing against the Queries feature of Textract. Queries allow you to ask questions about a document in natural language. If you have a vaccination for COVID-19, you can ask, "Who is the manufacturer for the first dose of COVID-19?" And it will return to the manufacturer.
Queries are priced at $0.015 per document.
For our comparison, we'll be using the same examples from this blog which introduced the Queries feature.
Generative AI
We will be using two generative AIs:
- GPT4 Vision
- Gemini Pro 1.0
GPT4 is priced at $0.01 per 1000 tokens. The image is tokenized, so it counts towards the total. Large images are automatically resized by the API.
Gemini is priced at $0.00025 per image + $0.000125 per 1000 input tokens + $0.000375 per 1000 output tokens.
Fortunately, both responses record the token usage so we can accurately calculate the cost.
Let's walkthrough the generative ocr code.
Here's the system prompt, which determines how our system will behave:
SYSTEM_MESSAGE = """You are given an image and a series of questions. Answer as succinctly as possible. Do not explain your reasoning for the answer, or add any additional wording, just give the answer.
For example, if the question is "What is the date?" and the answer is "January 1, 2022", you would respond with "January 1, 2022" and not "The date is January 1, 2022".
The questions have the following format:
QUESTIONS:
1. ...
2. ...
...
You will answer each question in order. If the answer is a numeric value, just return that numeric value. Use the following format for your answer:
ANSWERS:
1. ...
2. ...
..."""With any generative AI application, the bulk of the work is tailoring the prompt so that the AI is aligned with your task. In this case, I really want these core things:
- Set up the task.
- Answers contain only the answer and not some additional explanation to go along with it.
- Answers are in an easy format to parse.
Here's the OpenAI function:
def ocr_openai(
path_to_image: Path,
questions: List[str],
):
img = Image.open(path_to_image)
# grayscale
img = img.convert("L")
width, height = img.size
user_message = "QUESTIONS:\n"
for i, q in enumerate(questions):
user_message += f"{i+1}. {q}\n"
buf = BytesIO()
img.save(buf, format="JPEG")
base64_image = base64.b64encode(buf.getvalue()).decode("utf-8")
buf.close()
client = openai.OpenAI(api_key=api_key)
t0 = time.time()
completion = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "system",
"content": SYSTEM_MESSAGE,
},
{
"role": "user",
"content": [
{"type": "text", "text": user_message.strip()},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
},
],
},
],
max_tokens=2048,
temperature=0.1,
)
t1 = time.time()
print(f"Time taken: {t1 - t0:.2f} seconds")
content = completion.choices[0].message.content
total_tokens = completion.usage.total_tokens
print(
"Estimated cost based for image tokens on vision pricing calculator from https://openai.com/pricing."
)
print(f"TOTAL COST: {(total_tokens / 1000) * 0.01}")
answers = parse_response(content)
return answersHere's the Google function:
def ocr_google(
path_to_image: Path,
questions: List[str],
):
img = Image.open(path_to_image)
width, height = img.size
scale_factor = 1
# Gemini doesn't charge for image size so make it bigger to possibly help with accuracy
if width < 1000 or height < 1000:
scale_factor = 2
img = img.resize((int(width * scale_factor), int(height * scale_factor)))
# grayscale
img = img.convert("L")
buf = BytesIO()
img.save(buf, format="JPEG")
# decode in bytes
base64_image = base64.b64encode(buf.getvalue())
model = GenerativeModel("gemini-1.0-pro-vision")
buf.close()
user_message = "QUESTIONS:\n"
for i, q in enumerate(questions):
user_message += f"{i+1}. {q}\n"
image = Part.from_data(data=base64.b64decode(base64_image), mime_type="image/jpeg")
t0 = time.time()
responses = model.generate_content(
[SYSTEM_MESSAGE, image, user_message],
)
t1 = time.time()
print(f"Time taken: {t1 - t0:.2f} seconds")
total_cost = 0.0025 # image
# cost is per character not token
total_cost += ((len(SYSTEM_MESSAGE) + len(user_message)) / 1000) * 0.000125
total_cost += (len(responses.text) / 1000) * 0.000375
print(
f"Estimated cost based for image tokens on vision pricing calculator from https://cloud.google.com/vertex-ai/pricing."
)
print(f"TOTAL COST: {total_cost:.5f}")
content = responses.text
answers = parse_response(content)
return answers
Accuracy
Textract
In the post, they use four examples: vaccination, insurance, paystub, and mortgage. Each of these has its own series of questions relevant to the document.
In the blog post, they show perfect accuracy, but my own tests show otherwise. When asked the question "What is the MI?" when referring to the vaccination document, it responds as follows:
What is the MI?
No AnswerIf you look at the code example for this case, we see something entirely different. It's never asked, "What is the MI?" there but just
{
"Text": "MI",
"Alias": "MI_NUMBER"
}as part of the queries. And so it seems "What is the MI?" is not a built-in question, so in the example, they get the value for the label "MI" directly.
Based on this example, Textract appears less versatile. Phrasing the question as "MI" vs. "What is the MI" doesn't matter for the generative AI system.
Nonetheless, we will assume 100% accuracy for the Textract examples.
For timing comparisons, running the vaccination questions with Textract takes around 2–3 seconds.
Vaccination
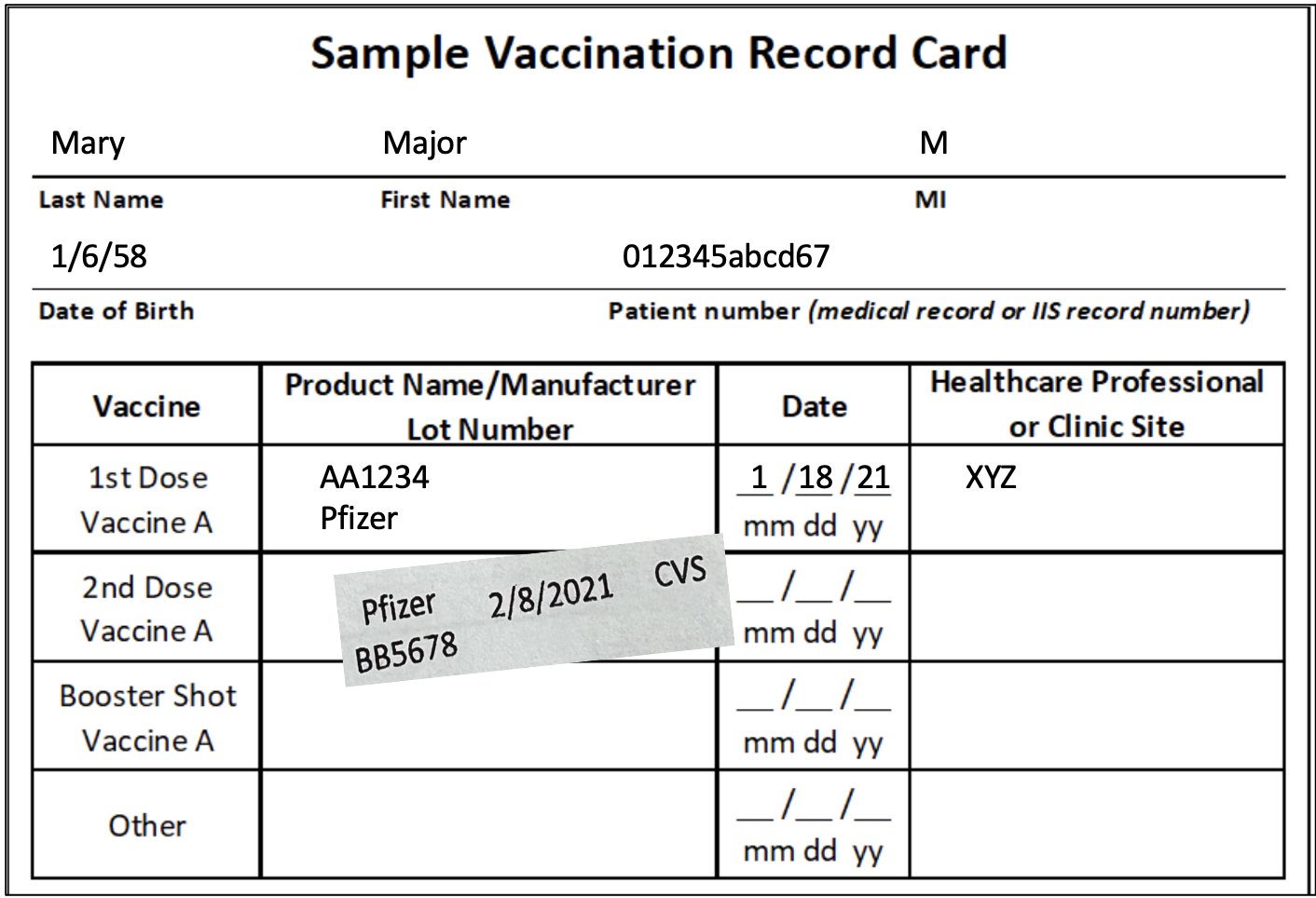
- What is the label first name value?
- What is the label last name value?
- Which clinic site was the 1st dose COVID-19 administrated?
- Who is the manufacturer for 1st dose of COVID-19?
- What is the date for the 2nd dose covid-19?
- What is the patient number?
- Who is the manufacturer for 2nd dose of COVID-19?
- Which clinic site was the 2nd dose covid-19 administrated?
- What is the lot number for 2nd dose covid-19?
- What is the date for the 1st dose covid-19?
- What is the lot number for 1st dose covid-19?
- What is the MI?
- MI?
$ python3.11 test.py --run_vaccination_tests=True --provider="openai"
...
Time taken: 6.50 seconds
TOTAL COST: 0.01511
Vaccination Tests: 13/13 (100.00% accuracy)
$ python3.11 test.py --run_vaccination_tests=True --provider="google"
...
Time taken: 4.06 seconds
TOTAL COST: 0.00261
Vaccination Tests: 13/13 (100.00% accuracy)Insurance
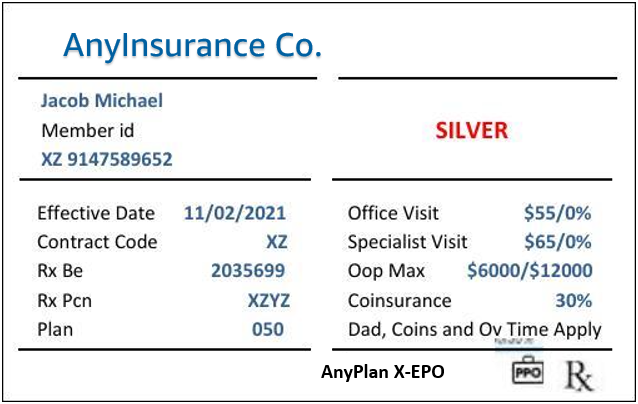
- What is the insured name?
- What is the level of benefits?
- What is medical insurance provider?
- What is the OOP max?
- What is the effective date?
- What is the office visit copay?
- What is the specialist visit copay?
- What is the member id?
- What is the plan type?
- What is the coinsurance amount?
$ python3.11 test.py --run_insurance_tests=True --provider="openai"
...
Time taken: 3.86 seconds
TOTAL COST: 0.00751
Insurance Tests: 10/10 (100.00% accuracy)
$ python3.11 test.py --run_insurance_tests=True --provider="google"
...
Time taken: 3.85 seconds
TOTAL COST: 0.00260
Insurance Tests: 10/10 (100.00% accuracy)Mortgage

- When is this document dated?
- What is the note date?
- When is the Maturity date the borrower has to pay in full?
- What is the note city and state?
- What is the yearly interest rate?
- Who is the lender?
- When does payments begin?
- What is the beginning date of payment?
- What is the initial monthly payments?
- What is the interest rate?
- What is the principal amount borrower has to pay?
$ python3.11 test.py --run_insurance_tests=True --provider="openai"
Time taken: 7.61 seconds
TOTAL COST: 0.01118
Mortgage Tests: 11/11 (100.00% accuracy)
$ python3.11 test.py --run_insurance_tests=True --provider="google"
Time taken: 3.63 seconds
TOTAL COST: 0.00260
Mortgage Tests: 11/11 (100.00% accuracy)Paystub

- What is the year to date gross pay?
- What is the current gross pay?
$ python3.11 test.py --run_paystub_tests=True --provider="openai"
Time taken: 4.53 seconds
TOTAL COST: 0.00966
Paystub Tests: 2/2 (100.00% accuracy)
$ python3.11 test.py --run_paystub_tests=True --provider="google"
Time taken: 3.43 seconds
TOTAL COST: 0.00256
Paystub Tests: 2/2 (100.00% accuracy)Accuracy Calculation
The accuracy is based on whether the response matches one of the valid answers.
QA(
question="What is the beginning date of payment?",
valid_answers=["April, 2022", "4/2022", "April 1, 2022", "4/1/22"],
),Multiple answers are only used if the value can have multiple formats, like a date. Although I believe we can improve this by feeding in a format the model should respond to for each question, something like: “What is the date (yyyy/mm/dd)”.
Truck Ticket Test
I decided to do a comparison on a document outside of the blog post dataset. This is a truck ticket commonly used in material transport logistics. The document was found on Google Images.
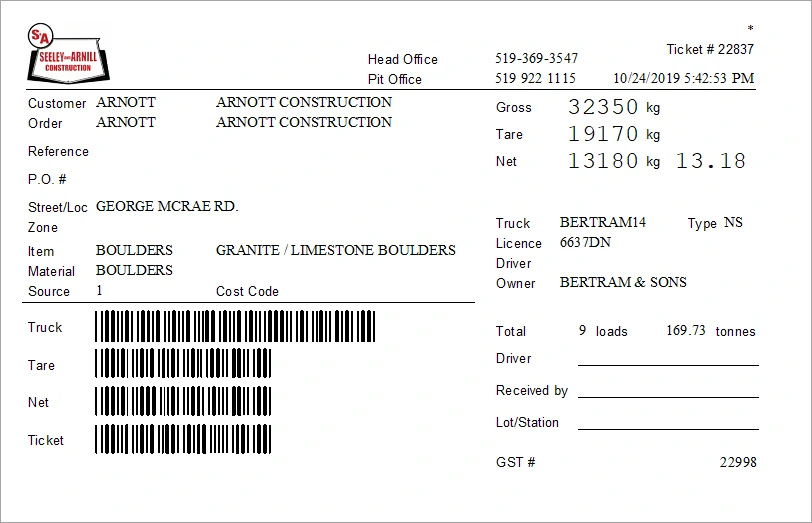
- What is the net payload?
- What is the net payload unit?
- What is the gross payload?
- What is the ticket number?
- What is the license plate?
- What is the truck identifier?
- What is the material being delivered?
- How many loads were delivered so far?
Textract does quite well here.
What is the net payload?
Answer: 13180 kg 13.18
Confidence: 0.4
What is the net payload unit?
Answer: 13180 kg 13.18
Confidence: 0.36
What is the gross payload?
Answer: 32350 kg
Confidence: 0.85
What is the ticket number?
Answer: 22837
Confidence: 0.98
What is the license plate?
Answer: 6637DN
Confidence: 0.99
What is the truck identifier?
Answer: BERTRAM14
Confidence: 0.99
What is the material being delivered?
Answer: BOULDERS
Confidence: 0.98
How many loads were delivered so far?
Answer: 9
Confidence: 0.97The only critique may be that it doesn't separate the quantity from the quantity unit.
Generative AI works as well.
python3.11 test.py --run_truckticket_tests=True --provider="openai"
...
1. 13180
2. kg
3. 32350
4. 22837
5. 6637DN
6. BERTRAM14
7. GRANITE / LIMESTONE BOULDERS
8. 9
Time taken: 4.53 seconds
TOTAL COST: 0.01054
python3.11 test.py --run_truckticket_tests=True --provider="google"
...
1. 13180
2. kg
3. 32350
4. 22837
5. 6637DN
6. BERTRAM14
7. BOULDERS
8. 9
Time taken: 3.61 seconds
TOTAL COST: 0.00264Conclusion
- Generative AI allows us to achieve comparable accuracy to Textract at a lower price. Initially, I did not think these would be the results. At the very least, I assumed the pricing would not be competitive with Textract, and perhaps an order of magnitude more expensive. Using Gemini proves to be significantly cheaper. You will probably never pay more than 3/10ths of a cent for a response. This means we can do 5 Gen AI OCR calls for 1 Textract call. OpenAI is also cheaper or comparatively priced.
- AWS Textract is 2-3x quicker in response.
- Scaling Laws: Generative AI will become more affordable and capable. It's not unreasonable to consider that by this time next year, costs will be 10x cheaper.
- It's not a perfect experiment. This does not mean you should use Gemini instead of Textract for OCR. Perhaps for your use case, Textract is a much better option. What this does mean is that perhaps you should think about it.
The most baffling part of all this is that a system with no intention of being useful for OCR is competitive across response time, accuracy, and cost with arguably the most robust OCR product on the market.